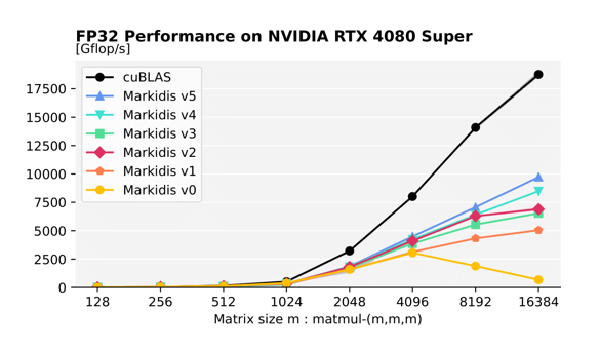
Recent GPUs often prioritize FP16 over FP32/FP64 operations. In this project, we devised & evaluated fast methods for approximating higher-precision matrix multiplication.
A highly optimized image encryption implementation outperforming a straightforward implementation by orders of magnitude and achieving 95% of theoretical scalar performance.